
An Introduction to Vector Databases: What You Need to Know

Have you ever experienced searching for something on the internet, but you can’t recall the precise term? Or perhaps you’re trying to locate something similar to what you’ve come across before, but it eludes you? If this sounds familiar, you’re in good company. This is where vector databases come into play. Vector databases represent a novel form of databases crafted to store and fetch information by gauging their likeness. Essentially, they enable you to discover items akin to your search, even when you lack the precise terminology.
In this blog, we will delve into the concept of vector databases – what they entail, their operational mechanics, and their practical applications. Moreover, we’ll explore the advantages and constraints associated with these databases.
What Exactly is a Vector Database?
A vector database is essentially a database that houses information in the form of high-dimensional vectors. Each vector serves as a representation of an individual piece of data, while the vector’s dimensions encapsulate the distinctive attributes of that data point. Consider an instance where a vector database is employed to store images; here, each vector would encode the pixel values of a particular image.
Vector databases are purposefully crafted to streamline the storage and retrieval of data by virtue of its resemblance. This stands in contrast to traditional relational databases, which primarily excel in storing and retrieving data based on precise matches. For instance, a vector database’s utility could shine when seeking out images akin to a specified reference image.
The Working of Vector Databases
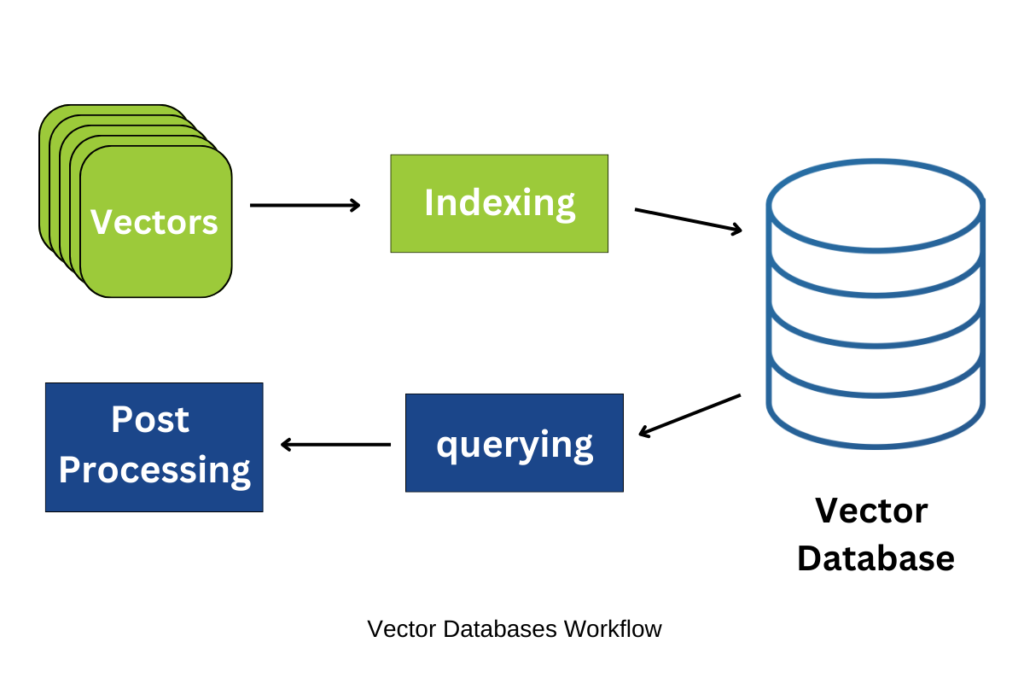
Vector databases employ an array of methodologies to ensure streamlined data storage and retrieval. Among these methods, one prevalent approach involves the utilization of a k-nearest neighbor (KNN) index. This index houses the distances separating each data point from its k closest neighbors. Consequently, the database can promptly pinpoint the k most analogous data points in response to a provided query vector.
Another frequently adopted approach entails the deployment of a hierarchical index. By employing this technique, the database effectively dissects the data space into a hierarchical series of progressively smaller segments. Consequently, the database can rapidly identify the data points situated within a specified region.
Vector databases derive their potency from a synergy of diverse algorithms, working in tandem to facilitate what is known as Approximate Nearest Neighbor (ANN) search. This collaborative effort uses algorithms that perform the search process through various other methods like hashing, quantization, and exploration based on graphs.
The Advantages of Vector Database
The merits of integrating a vector database into your operations are manifold. To begin with, these databases exhibit remarkable adeptness in both storing and swiftly retrieving data based on their resemblances. This attribute positions them as optimal choices for tasks reliant on similarity searches, such as image exploration, recommendation systems, and natural language processing.
Moreover, vector databases shine in terms of scalability. They proficiently accommodate large volumes of data, ensuring efficient storage and retrieval. This renders them particularly well-suited for endeavors grappling with substantial data loads, including endeavors like big data analytics and machine learning.
In addition to their efficiency and scalability, vector databases tout flexibility as another asset. They capably accommodate a diverse array of data types, spanning text, images, audio, and video. As such, they emerge as versatile solutions, catering aptly to an array of applications.
The Constraints of Employing a Vector Database
While leveraging a vector database offers numerous advantages, certain limitations warrant consideration. Firstly, it’s important to note that the upfront cost associated with vector databases could potentially surpass that of conventional relational databases. This is attributable to the intricate indexing and querying methods integral to their functioning.
Secondly, it’s worth acknowledging that vector databases can present a steeper learning curve and usability challenge compared to traditional relational databases. Utilizing them effectively demands a more profound grasp of concepts pertaining to similarity search and machine learning techniques.
Diverse Applications of Vector Databases
Vector databases exhibit versatile utility across various domains, including:
Image Search: Harnessing vector databases facilitates the discovery of images akin to a designated reference image. This proves invaluable for endeavors encompassing product searches, social media interactions, and e-commerce pursuits.
Recommendation Systems: Employing vector databases aids in furnishing users with personalized product or service recommendations grounded in their historical interactions. This optimization contributes to enhanced user engagement and amplified sales figures.
Natural Language Processing: Vector databases assume a pivotal role in processing natural language text. They empower applications such as machine translation, sentiment analysis, and question-answering, fostering seamless communication and comprehension.
Fraud Detection: Vector databases bolster fraud detection endeavors by scrutinizing transactions against recognized fraud patterns. This serves to safeguard businesses and consumers alike from financial perils.
Biometric Identification: Leveraging vector databases streamlines the identification of individuals through biometric markers like fingerprints and facial attributes. Applications encompass security reinforcement, access control, and advancements in healthcare realms.
These are just a few examples of how vector databases can be used. As the technology improves, we’ll likely discover even more remarkable and creative ways to use them.
A Shining Future for Vector Databases
The trajectory of vector databases is imbued with optimism. With the burgeoning volume of data and the escalating demand for efficient and scalable data storage and retrieval solutions, the role of vector databases is poised to become progressively indispensable.
Moreover, the evolution of novel machine learning and artificial intelligence techniques is ushering in fresh prospects for vector databases. For instance, these databases can serve as training grounds for machine learning models, equipping them to discern patterns and correlations within data. This holds the potential to enhance vector database performance across a spectrum of applications.
All in all, the road ahead for vector databases appears promising. As a potent technological innovation, they harbor the capability to redefine the paradigms governing data storage, retrieval, and analysis.
Which Vector Database Should I Choose?
Multiple vector databases are available, and among the top contenders are the following:
Weaviate stands as a versatile vector database, acknowledged for its user-friendly interface and effortless deployment.
Milvus offers scalability as its forte, tailored to cater to the demands of big data analytics.
Pinecone emerges as a fully managed vector database, streamlining the integration of vector search into live applications.
Chroma boasts a featherweight profile and user-friendliness, serving as an ideal vector database for constructing AI applications.
Additional alternatives encompass Vespa and Qdrant.
Determining the optimal vector database hinges on your specific prerequisites and demands.
In Conclusion
Vector databases represent a robust and innovative technology, offering efficient data storage and retrieval capabilities. Their suitability shines particularly in applications necessitating similarity searches, spanning domains like image exploration, recommendation systems, and natural language processing. If you’re in search of a database capable of seamlessly managing substantial data loads while swiftly executing similarity searches, a vector database emerges as a fitting choice.
Whether it’s finding similar images or enhancing big data analytics, Appfoster’s expertise ensures optimal database selection and implementation for your specific needs. Get in Touch with us today!